Mosaic AI Vector Search
この記事では、Databricksのベクトル検索ソリューション、Mosaic AI Vector Searchの概要と、それが何であるか、どのように機能するかについて説明します。
Mosaic AI Vector Searchとは
Mosaic AI Vector Searchは、Databricksのデータインテリジェンスプラットフォームに組み込まれ、ガバナンスツールや生産性向上ツールと統合されたベクトルデータベースです。ベクトルデータベースは、埋め込みデータを格納・検索するために最適化されたデータベースです。埋め込みは、データ(通常はテキストまたは画像データ)のセマンティックコンテンツを数学的に表現したものです。埋め込みは大規模言語モデルによって生成され、互いに類似した文書や画像を見つけることに依存する多くの生成AIアプリケーションの重要な要素です。例としては、RAGシステム、推薦システム、画像および動画認識があります。
Mosaic AI Vector Searchを使用すると、Deltaテーブルからベクトル検索インデックスを作成できます。インデックスにはメタデータを含む埋め込みデータが含まれます。その後、REST APIを使用してインデックスをクエリーし、最も類似したベクトルを特定し、関連するドキュメントを返すことができます。基礎となるDeltaテーブルが更新されると、自動的に同期するようにインデックスを構成することができます。
Mosaic AI Vector Search では、次の機能がサポートされています。
Mosaic AI Vector Searchはどのように機能しますか?
Mosaic AI Vector Searchは、近似最近傍探索にHNSW(Hierarchical Navigable Small World)アルゴリズムを使用し、埋め込みベクトルの類似度を測定するためにL2距離メトリクスを使用します。コサイン類似度を使用する場合は、データポイントの埋め込みを正規化してからベクトル検索に入力する必要があります。データポイントが正規化されると、L2距離によって生成されるランキングは、余弦類似度によって生成されるランキングと同じになります。
Mosaic AI Vector Searchは、ベクトルベースの埋め込み検索と従来のキーワードベースの検索技術を組み合わせた、ハイブリッドキーワード類似検索もサポートしています。このアプローチでは、クエリー内の単語を正確に一致させると同時に、ベクトルベースの類似性検索を使用してクエリーのセマンティック関係とコンテキストを取得します。
これら2つの技術を統合することで、ハイブリッドキーワード類似検索は、正確なキーワードだけでなく、概念的に類似したキーワードを含むドキュメントも検索し、より包括的で関連性の高い検索結果を提供します。このメソッドは、ソースデータにSKUや識別子のような一意のキーワードがあり、純粋な類似検索に適していないRAGアプリケーションで特に有効です。
APIの詳細については、 Python SDKリファレンス と ベクトル検索エンドポイントをクエリーするを参照してください。
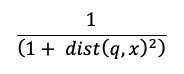
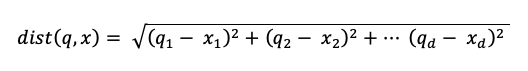
キーワード検索アルゴリズム
関連性スコアはOkapi BM25を使用して計算されます。ソーステキストの埋め込み列や、テキストまたは文字列形式のメタデータ列を含む、すべてのテキストまたは文字列列が検索されます。トークン化機能は、単語の境界で分割し、句読点を削除し、すべてのテキストを小文字に変換します。
類似検索とキーワード検索を組み合わせる方法
類似検索とキーワード検索の結果は、Reciprocal Rank Fusion(RRF)機能を使用して結合されます。
RRFは、スコアを使用して各メソッドからの各ドキュメントを再スコアリングします。
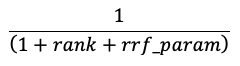
上の式では、ランクは0から始まり、各ドキュメントのスコアを合計して、最もスコアの高いドキュメントを返します。
rrf_param 上位ランクのドキュメントと下位ランクのドキュメントの相対的な重要度を制御します。文献に基づいて、 rrf_paramは60に設定されています。
スコアは、以下の式を用いて最高スコアを1、最低スコアを0とするように正規化されます:
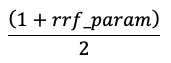
ベクトルエンべディングを提供するためのオプション
Databricksでベクトルデータベースを作成するには、まずベクトルの埋め込みをどのように行うかを決定する必要があります。Databricksは次の3つのオプションをサポートしています。
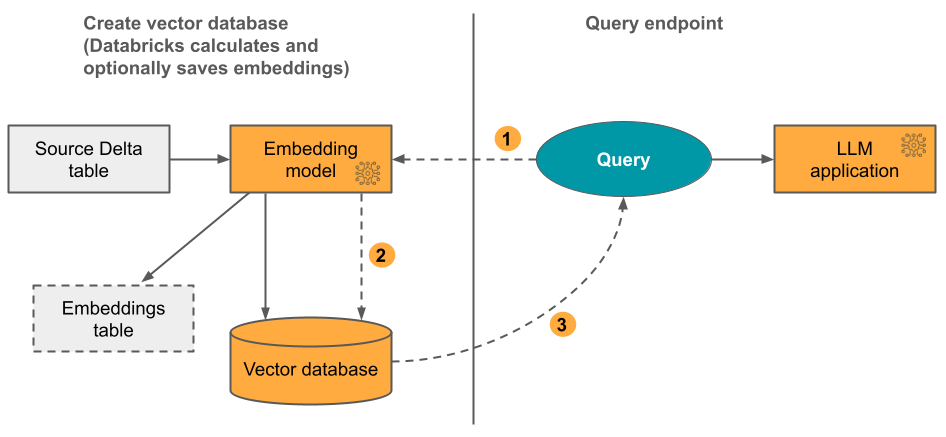
オプション1:Delta による埋め込みコンピュートとのDatabricks インデックスの同期 テキスト形式のデータを含むソースDelta テーブルを提供します。Databricks は、指定したモデルを使用して埋め込みを計算し、必要に応じて埋め込みを Unity Catalog のテーブルに保存します。 Delta テーブルが更新されても、インデックスは Delta テーブルと同期されたままになります。
次の図は、このプロセスを示しています。
クエリーの埋め込みを計算します。クエリーにはメタデータフィルターを含めることができます。
最も関連性の高い文書を特定するために類似検索を実行します。
最も関連性の高い文書を返し、クエリーに追加します。
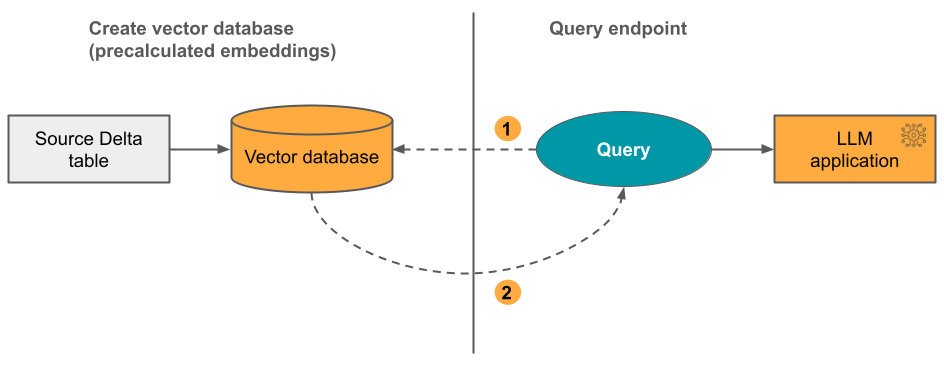
オプション 2: 自己管理型の埋め込みを使用した Delta Sync Index 事前に計算された埋め込みを含むソース Delta テーブルを指定します。 Delta テーブルが更新されても、インデックスは Delta テーブルと同期されたままになります。
次の図は、このプロセスを示しています。
クエリーは埋め込みで構成され、メタデータフィルターを含めることができます。
類似性検索を実行して、最も関連性の高いドキュメントを特定します。最も関連性の高いドキュメントを返し、クエリーに追加します。
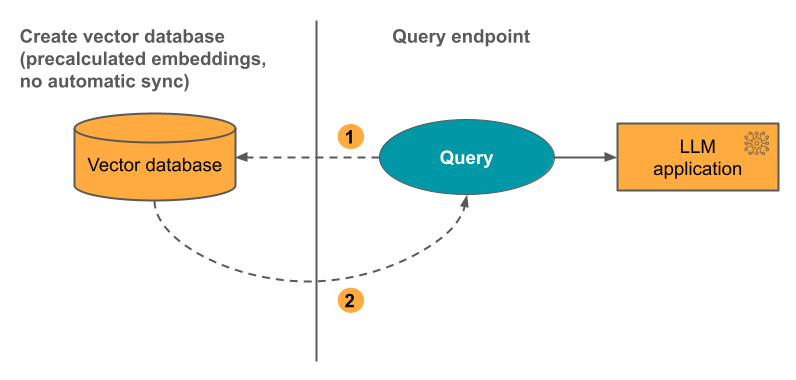
オプション 3: Direct Vector Access Index 埋め込みテーブルが変更された場合は、REST API を使用してインデックスを手動で更新する必要があります。
次の図は、このプロセスを示しています。
Mosaic AI Vector Searchの設定方法
Mosaic AI Vector Searchを使用するには、以下を作成する必要があります。
ベクトル検索エンドポイント。このエンドポイントは、ベクトル検索インデックスを提供します。REST APIまたはSDKを使用してエンドポイントをクエリーおよび更新できます。手順については、ベクトル検索エンドポイントの作成を参照してください。
エンドポイントは、インデックスのサイズまたは並列要求の数をサポートするために自動的にスケールアップします。 エンドポイントは自動的にスケールダウンされません。
ベクトル検索インデックスベクトル検索インデックスはDeltaテーブルから作成され、リアルタイムの近似最近傍検索を提供するように最適化されています。検索の目的は、クエリーと類似した文書を特定することです。ベクター検索インデックスはUnityカタログに表示され、Unityカタログによって管理されます。手順については、ベクトル検索インデックスの作成を参照してください。
さらにDatabricksに埋め込みを許可する場合は、事前構成されたインフラストラクチャAPIsエンドポイントを使用するか、モデル サービス エンドポイントを作成して、選択した埋め込みモデルを提供できます。手順については、トークン単位の従量課金基盤モデルAPIsまたは基盤モデル提供エンドポイントの作成を参照してください。
モデルサービングエンドポイントをクエリーするには、REST APIまたはPython SDKのいずれかを使用します。クエリーは、Deltaテーブルの任意のカラムに基づいたフィルターを定義することができます。詳細については、クエリでフィルターを使用する、APIリファレンス、または、Python SDKリファレンスを参照してください。
要件
Unity Catalog対応ワークスペースであること。
サーバレス コンピュート enabled. 手順については、 サーバレス コンピュートへの接続を参照してください。
ソース テーブルでは、チェンジデータフィードが有効になっている必要があります。 手順については、 でのDelta Lake チェンジデータフィードの使用Databricks を参照してください。
ベクトル検索インデックスを作成するには、インデックスが作成されるカタログスキーマに対する CREATE TABLE 権限が必要です。
ベクトル検索エンドポイントを作成および管理するためのアクセス許可は、アクセス制御リストを使用して構成されます。 ベクトル検索エンドポイント ACLを参照してください。
データ保護と認証
Databricksでは、データを保護するために次のセキュリティ制御機能を実装しています。
Mosaic AI Vector Searchに対するすべての顧客のリクエストは、論理的に分離され、認証され、承認されます。
Mosaic AI Vector Searchは、保存中(AES-256)と転送中(TLS 1.2+)のすべてのデータを暗号化します。
Mosaic AI Vector Searchは、次の2つの認証モードをサポートしています。
サービスプリンシパル トークン. 管理者は、サービスプリンシパル トークンを生成し、それを SDK または APIに渡すことができます。 「サービスプリンシパルを使用する」を参照してください。本番運用のユースケースでは、 Databricks はサービスプリンシパル トークンを使用することをお勧めします。
# Pass in a service principal vsc = VectorSearchClient(workspace_url="...", service_principal_client_id="...", service_principal_client_secret="..." )
個人用アクセストークン。 個人用アクセス トークンを使用して、 Mosaic AI Vector Searchで認証できます。 「personal access authentication トークン」を参照してください。ノートブック環境で SDK を使用する場合、SDK は認証用の PAT トークンを自動的に生成します。
# Pass in the PAT token client = VectorSearchClient(workspace_url="...", personal_access_token="...")
カスタマーマネージドキー(CMK)は、2024年5月8日以降に作成されたエンドポイントでサポートされます。
使用状況とコストを監視する
課金利用システムテーブルを使用すると、ベクトル検索インデックスとエンドポイントに関連する使用量とコストを監視することができます。クエリーの例を次に示します。
WITH all_vector_search_usage (
SELECT *,
CASE WHEN usage_metadata.endpoint_name IS NULL THEN 'ingest'
WHEN usage_type = "STORAGE_SPACE" THEN 'storage'
ELSE 'serving'
END as workload_type
FROM system.billing.usage
WHERE billing_origin_product = 'VECTOR_SEARCH'
),
daily_dbus AS (
SELECT workspace_id,
cloud,
usage_date,
workload_type,
usage_metadata.endpoint_name as vector_search_endpoint,
CASE WHEN workload_type = 'serving' THEN SUM(usage_quantity)
WHEN workload_type = 'ingest' THEN SUM(usage_quantity)
ELSE null
END as dbus,
CASE WHEN workload_type = 'storage' THEN SUM(usage_quantity)
ELSE null
END as dsus
FROM all_vector_search_usage
GROUP BY all
ORDER BY 1,2,3,4,5 DESC
)
SELECT * FROM daily_dbus
課金利用テーブルの内容の詳細については、課金利用システムテーブルリファレンスを参照してください。その他のクエリーは以下のノートブックの例にあります。
リソースとデータサイズの上限
次の表は、ベクトル検索のエンドポイントとインデックスに対するリソースとデータサイズの上限を示しています。
リソース |
粒度 |
上限 |
|---|---|---|
ベクトル検索エンドポイント |
ワークスペースごと |
100 |
埋め込み |
エンドポイントごと |
320,000,000 |
埋め込みサイズ |
インデックスごと |
4096 |
インデックス |
エンドポイントごと |
50 |
列 |
インデックスごと |
50 |
列 |
サポートされているタイプ:バイト、short、integer、long、float、double、boolean、文字列、タイムスタンプ、日付 |
|
メタデータフィールド |
インデックスごと |
50 |
インデックス名 |
インデックスごと |
128文字 |
ベクトル検索のインデックスの作成と更新には、次の上限が適用されます。
リソース |
粒度 |
上限 |
|---|---|---|
Delta Syncインデックスの行サイズ |
インデックスごと |
100KB |
Delta Syncインデックスの埋め込みソース列サイズ |
インデックスごと |
32764バイト |
Direct Vectorインデックスの一括アップサートリクエストのサイズ |
インデックスごと |
10MB |
Direct Vectorインデックスの一括削除リクエストのサイズ |
インデックスごと |
10MB |
クエリーAPIには、次の制限が適用されます。
リソース |
粒度 |
上限 |
|---|---|---|
クエリテキストの長さ |
クエリごと |
32764バイト |
返される結果の最大数 |
クエリごと |
10,000 |