Controle de acesso refinado em computação dedicada (anteriormente computação de usuário único)
Este artigo apresenta a funcionalidade de filtragem de dados que permite o controle de acesso refinado em consultas que são executadas em compute dedicado (all-purpose ou Job compute configurado com o modo de acesso Dedicated ). Consulte Modos de acesso.
Essa filtragem de dados é realizada nos bastidores usando o site serverless compute.
Por que algumas consultas em computação dedicada exigem filtragem de dados?
Unity Catalog permite controlar o acesso a dados tabulares no nível da coluna e da linha (também conhecido como controle de acesso refinado) usando o seguinte recurso:
Quando os usuários consultam visualizações que excluem dados de tabelas referenciadas ou consultam tabelas que aplicam filtros e máscaras, eles podem usar qualquer um dos seguintes compute recurso sem limitações:
SQL warehouses
Padrão compute (anteriormente compartilhado compute)
No entanto, se o senhor usar o compute dedicado para executar essas consultas, o compute e o workspace deverão atender a requisitos específicos:
O recurso dedicado compute deve estar em Databricks Runtime 15.4 LTS ou acima.
O workspace deve estar habilitado para serverless compute para Job, Notebook e Delta Live Tables.
Para confirmar que sua região workspace suporta serverless compute, consulte recurso com disponibilidade regional limitada.
Se o compute recurso e o workspace dedicados atenderem a esses requisitos, a filtragem de dados será executada automaticamente sempre que o senhor consultar um view ou uma tabela que use controle de acesso refinado.
Suporte para visualização materializada, tabelas de transmissão e visualização padrão
Além da visualização dinâmica, os filtros de linha e a filtragem de dados de mascaramento de coluna também permitem consultas na visualização e nas tabelas a seguir que não são compatíveis com o site dedicado compute que está executando o Databricks Runtime 15.3 e abaixo:
No site compute dedicado que executa o Databricks Runtime 15.3 e abaixo, o usuário que executa a consulta no view deve ter SELECT nas tabelas e na visualização referenciadas pelo view, o que significa que não é possível usar a visualização para fornecer controle de acesso refinado. No site Databricks Runtime 15.4 com filtragem de dados, o usuário que consulta o site view não precisa acessar as tabelas e a visualização referenciadas.
Como a filtragem de dados funciona na computação dedicada?
Sempre que uma consulta acessa os seguintes objetos de banco de dados, o recurso dedicado compute passa a consulta para serverless compute para realizar a filtragem de dados:
visualização criada sobre tabelas nas quais o usuário não tem o privilégio
SELECTVisualização dinâmica
Tabelas com filtros de linha ou máscaras de coluna definidas
Visualização materializada e tabelas de transmissão
No diagrama a seguir, um usuário tem SELECT em table_1, view_2 e table_w_rls, que tem filtros de linha aplicados. O usuário não tem SELECT em table_2, que é referenciado por view_2.
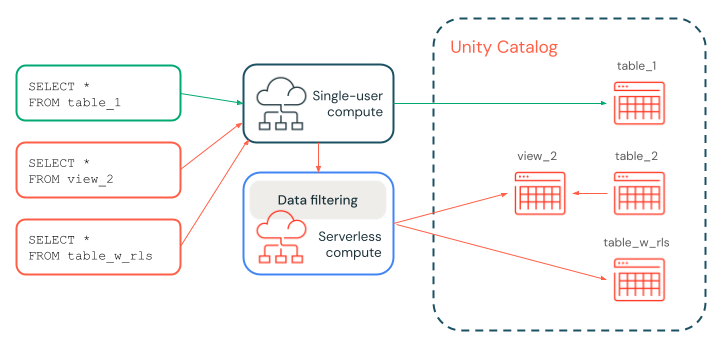
A consulta em table_1 é tratada inteiramente pelo recurso dedicado compute, pois não é necessária nenhuma filtragem. As consultas em view_2 e table_w_rls exigem filtragem de dados para retornar os dados aos quais o usuário tem acesso. Essas consultas são tratadas pelo recurso de filtragem de dados em serverless compute.
Quais são os custos incorridos?
Os clientes são cobrados pelo recurso serverless compute que é usado para realizar operações de filtragem de dados. Para obter informações sobre preços, consulte Platform Tiers and Add-Ons.
O senhor pode consultar a tabela de uso de faturamento do sistema para ver o quanto foi cobrado. Por exemplo, a consulta a seguir detalha os custos do compute por usuário:
SELECT usage_date,
sku_name,
identity_metadata.run_as,
SUM(usage_quantity) AS `DBUs consumed by FGAC`
FROM system.billing.usage
WHERE usage_date BETWEEN '2024-08-01' AND '2024-09-01'
AND billing_origin_product = 'FINE_GRAINED_ACCESS_CONTROL'
GROUP BY 1, 2, 3 ORDER BY 1;
Visualizar o desempenho da consulta quando a filtragem de dados está ativada
O site Spark UI para compute dedicado exibe métricas que o senhor pode usar para entender o desempenho de suas consultas. Para cada consulta que o senhor executar no recurso compute, o SQL/Dataframe tab exibe a representação gráfica da consulta. Se uma consulta estiver envolvida na filtragem de dados, a interface do usuário exibirá um nó de operador RemoteSparkConnectScan na parte inferior do gráfico. Esse nó exibe métricas que o senhor pode usar para investigar o desempenho da consulta. Consulte a visualização de compute informações na UI de Apache Spark .
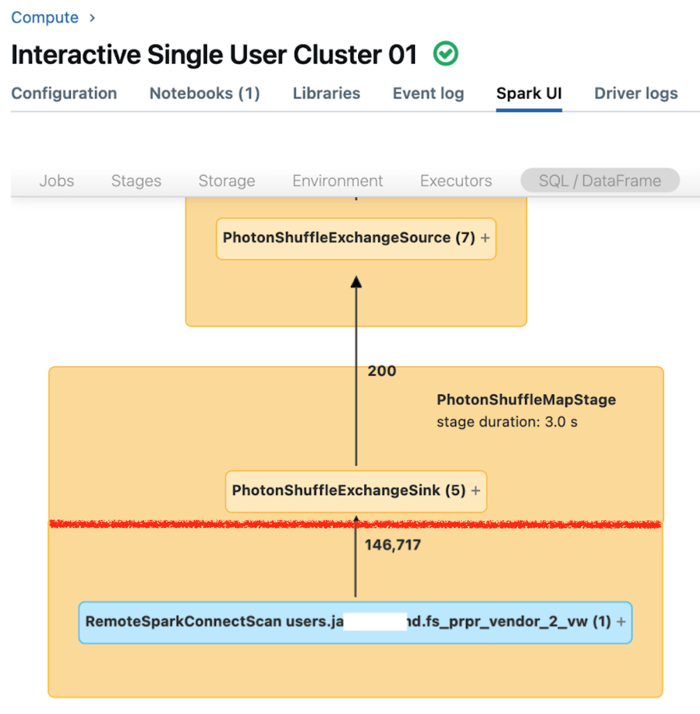
Expanda o nó do operador RemoteSparkConnectScan para ver as métricas que abordam questões como as seguintes:
Quanto tempo foi gasto na filtragem de dados? view "tempo total de execução remota".
Quantas linhas restaram após a filtragem de dados? view "saída de linhas".
Quantos dados (em bytes) foram retornados após a filtragem de dados? view "tamanho da saída das linhas".
Quantos arquivos de dados foram podados por partição e não precisaram ser lidos do armazenamento? view "Files pruned" (Arquivos removidos) e "Size of files pruned" (Tamanho dos arquivos removidos).
Quantos arquivos de dados não puderam ser podados e tiveram de ser lidos do armazenamento? view "Arquivos lidos" e "Tamanho dos arquivos lidos".
Dos arquivos que precisavam ser lidos, quantos já estavam no cache? view "O cache atinge o tamanho" e "O cache perde o tamanho".
Limitações
Não há suporte para operações de gravação ou refresh em tabelas que tenham filtros de linha ou máscaras de coluna aplicadas.
Especificamente, não há suporte para operações DML, como
INSERT,DELETE,UPDATE,REFRESH TABLEeMERGE. O senhor só pode ler (SELECT) nessas tabelas.As autouniões são bloqueadas pelo site default quando a filtragem de dados é chamada, mas é possível permiti-las definindo
spark.databricks.remoteFiltering.blockSelfJoinscomo false no site compute em que o comando está sendo executado.Antes de ativar o self-join em um recurso compute dedicado, esteja ciente de que uma consulta self-join tratada pelo recurso de filtragem de dados pode retornar diferentes Snapshot da mesma tabela remota.
Se o seu workspace foi implantado com um firewall antes de novembro de 2024, o senhor deve abrir as portas 8443 e 8444 para permitir o controle de acesso refinado no compute dedicado. Consulte Grupos de segurança.