Delta Sharingオープン共有を使用して共有されたデータを読み取る(受信者向け)
February 11, 2025
この記事では、Delta Sharing オープン共有 プロトコルを使用して共有されたデータを読み取る方法について説明します。 これには、 Databricks、 Apache Spark、 Pandas、 Power BI、および Tableauを使用して共有データを読み取る手順が含まれています。
オープン共有では、データ プロバイダーによってチームのメンバーと共有された資格情報ファイルを使用して、共有データへの安全な読み取りアクセスを取得します。 資格情報が有効で、プロバイダーが引き続きデータを共有する限り、アクセスは保持されます。 プロバイダーは、資格情報の有効期限とローテーションを管理します。 データの更新はほぼリアルタイムで利用できます。 共有データの読み取りとコピーは可能ですが、ソースデータを変更することはできません。
注:
Databricks 間 Delta Sharing を使用してデータが共有されている場合、データにアクセスするために資格情報ファイルは必要なく、この記事は適用されません。 手順については、「 Databricks間Delta Sharing (受信者用) を使用して共有されたデータを読み取る」を参照してください。
次のセクションでは、 Databricks 、 Apache Spark 、 Pandas 、 Power BIを使用して資格情報ファイルを共有データにアクセスし、読み取る方法について説明します。 Delta Sharingコネクタの完全なリストとその使用方法については、 Delta Sharingオープンソース ドキュメントを参照してください。 共有データにアクセスする際に問題が発生した場合は、データ プロバイダーにお問い合わせください。
注:
パートナー統合は、特に記載がない限り、サードパーティによって提供されており、その製品およびサービスを使用するには、適切なプロバイダーのアカウントを持っている必要があります。 Databricks は、このコンテンツを最新の状態に保つために最善を尽くしていますが、パートナー統合ページの統合またはコンテンツの正確性については一切表明しません。 統合に関して、適切なプロバイダーに連絡してください。
始める前に
チームのメンバーは、データ プロバイダーによって共有される資格情報ファイルをダウンロードする必要があります。 「オープン共有モデルでアクセスを取得する」を参照してください。
そのファイルまたはファイルの場所をあなたと共有するには、安全なチャンネルを使用する必要があります。
Databricks: オープンな共有コネクタを使用して共有データを読み取る
このセクションでは、Catalog Explorer または Python ノートブックでプロバイダーの資格情報ファイルを使用してプロバイダーをインポートする方法について説明します。 ノートブックの手順では、ノートブックを使用して共有テーブルを一覧表示および読み取る方法についても説明します。 カタログエクスプローラーを使用してインポートされた共有データを読み取るには、「Databricks-to-Databricks Delta Sharingを使用して共有データを読み取る(受信者向け)」を参照してください。
注:
データ プロバイダーが Databricks 間の共有を使用していて、資格情報ファイルを共有していない場合は、 Unity Catalog を使用してデータにアクセスする必要があります。 手順については、「 Databricks間Delta Sharing (受信者用) を使用して共有されたデータを読み取る」を参照してください。
必要なアクセス許可: メタストア管理者、または Unity Catalog メタストアに対する CREATE PROVIDER 権限と USE PROVIDER 権限の両方を持つユーザー。
Databricks ワークスペースで、
 [カタログ]をクリックしてカタログエクスプローラーを開きます。
[カタログ]をクリックしてカタログエクスプローラーを開きます。[カタログ] ウィンドウの上部にある [
 ] 歯車アイコンをクリックし、[Delta Sharing] を選択します。
] 歯車アイコンをクリックし、[Delta Sharing] を選択します。または、[ クイック アクセス ] ページで [Delta Sharing > ] ボタンをクリックします。
[ 自分と共有] タブで、ページの右上隅にある [ プロバイダーを直接インポート] をクリックします。
ドロップダウンメニューからプロバイダーを選択するか、名前を入力します。
プロバイダーから共有された資格情報ファイルをアップロードします。 さまざまなプロバイダーの具体的な手順を読むことができます。
(オプション)コメントを入力します。
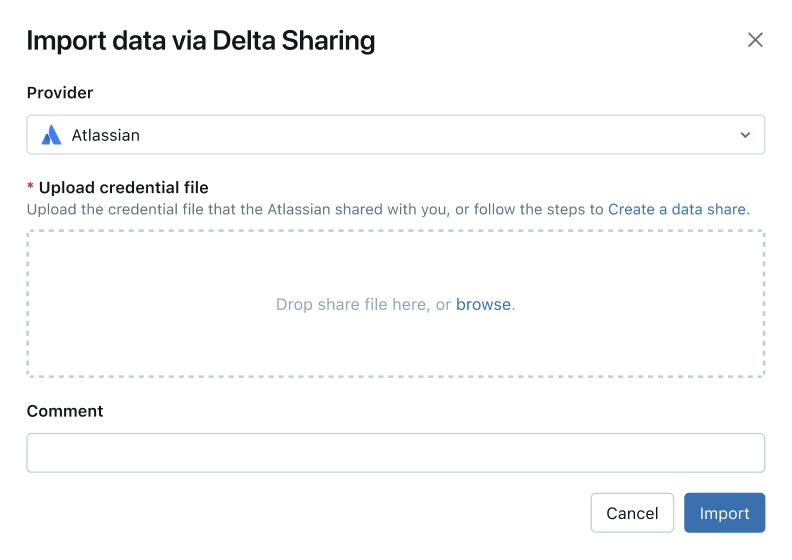
「インポート」をクリックします。
共有データからカタログを作成します。
このプロセスは、 Databricks-to-Databricks 共有モデルと同じです。
「共有からのカタログの作成」を参照してください。
カタログへのアクセス権を付与します。
「 共有データをチームで利用できるようにするにはどうすればよいですか?」を参照してください。 Delta Sharingカタログ内のスキーマ、テーブル、ボリュームのアクセス許可の管理。
共有データ オブジェクトは、Unity Catalog に登録されているデータ オブジェクトと同様に読み取ります。
詳細と例については、 共有テーブルまたはボリューム内のデータへのアクセスを参照してください。
 で x をクリックします。
で x をクリックします。